

Testing GenAI Products: Lesson from software engineering principles

You're not building AI products.
There, I said it. The moment you decided to integrate OpenAI models into your product, you stopped building an AI system and started building a software product. Yet, your testing strategy probably hasn't caught up with this reality.
Think about it: When was the last time a user cared about your model's perplexity scores or your fine-tuning datasets? What they care about is whether your AI-powered email assistant can actually write emails that sound like them.
Your customer success team isn't losing sleep over embedding dimensions – they're worried about response times and API costs.
The hard truth is that most GenAI products today are essentially API-first SaaS applications. You're not training models; you're consuming them. You're not tweaking hyperparameters; you're designing user experiences. The sooner we acknowledge this shift, the better we can test these products.
Consider an AI-powered CRM system. Its core challenges aren't in model architecture – they're in system integration, user experience, and business logic.
When it fails, it's rarely because of model limitations. It fails because we didn't test how it handles a sales representative's actual workflow,
or because we didn't consider what happens when the API is slow,
or because we didn't validate that the generated content aligns with company guidelines.
This fundamental reframing isn't just semantic – it's strategic. It means your testing approach needs to shift from AI metrics to software quality attributes.
It means your test cases should focus more on user scenarios than model behaviors. Most importantly, it means you can leverage decades of software testing wisdom while addressing the unique challenges that GenAI brings to the table.
The Unique Testing Landscape of GenAI Applications
While GenAI products are software applications at their core, they introduce complexities that traditional testing approaches weren't designed to handle. Understanding these unique challenges is crucial for developing effective testing strategies.
Beyond Traditional Unit Testing
Traditional unit testing relies on deterministic inputs and outputs. Given input A, expect output B. GenAI shatters this paradigm. The same prompt can generate different responses, each technically correct but varying in style, tone, and content. This stochastic nature fundamentally changes how we approach testing.
Consider testing a function that generates product descriptions. Traditional unit tests would fail because:
The output length varies
Word choice and sentence structure change between runs
The order of information might differ
All versions might be equally valid
Instead of exact matching, we need to test for:
Semantic correctness
Inclusion of required information
Adherence to style guidelines
Avoidance of prohibited content
Context-Dependent Behavior
GenAI responses depend heavily on context, making testing more complex. The same function might need different testing approaches based on:
User personas (technical vs. non-technical users)
Industry context (healthcare vs. entertainment)
Geographic and cultural considerations
Regulatory requirements
Key Testing Considerations
Hallucination Detection:
Systematic testing for factual accuracy
Detection of made-up references or statistics
Validation against known truth sets
Testing with ambiguous inputs
Security and Prompt Injection:
Testing for prompt injection vulnerabilities
Validation of content filtering
Testing of rate limiting and abuse prevention
Security testing of prompt handling
Response Guardrails:
Testing of content filtering mechanisms
Validation of tone and style consistency
Testing of fallback mechanisms (human in the loop)
Handling of edge cases and errors
Performance and Cost:
Token usage optimization
Response time testing
Cost per request monitoring
Batch processing efficiency
Establishing Testing Standards and Benchmarks
Creating standards for GenAI testing requires balancing traditional software metrics with AI-specific considerations. Here's how to establish what "good" looks like:
Response Quality Metrics
Accuracy Metrics:
Factual correctness rate
Hallucination frequency
Source attribution accuracy
Context relevance scores
Consistency Metrics:
Style adherence
Tone consistency
Format compliance
Brand alignment
Performance Metrics:
Response time distributions
Token utilization efficiency
Error rates and types
API availability
Creating Continuous Evaluation Frameworks
Automated Testing Pipeline:
Regular regression testing
Performance benchmark tracking
Cost monitoring
Quality metric tracking
Version Control for AI Components:
Prompt version management
Configuration tracking
Test case versioning
Result comparison across versions
Evaluation Sets
Domain-Specific Test Cases:
Prepare Industry-specific scenarios, what happens when <X> situation occurs
Common user workflows, how each persona interacts with the product
Edge cases and error conditions. Softwares fail, how will AI respond.
Compliance requirements
Benchmark Datasets:
Prepare variations of request and response data based on ideal persona inputs
Known challenging cases. Try to break the system.
Historical issues when AI is proven to hallucinate
Competitor comparison cases
Practical Implementation Guide
So how to build systematic approach that combines traditional software testing practices with AI-specific considerations ?
Manual Testing Foundation
Expert Review Process:
Validate the responses by Subject matter expert
Content quality assessment
User experience and user journey evaluation
Business logic verification
User Acceptance Testing:
A/B testing programs, try to test same prompt with different situations
Collect the User feedback with each variation
Usage pattern analysis
Iteration based on findings
Prompt Engineering Validation:
Systematic prompt testing. Test the prompt variations.
Edge case identification
Prompt optimization based on which variations work best
Version control prompts in github
Creating Persona-Based Test Data
User Archetype Definition:
Detailed persona descriptions
Use case mapping, non tech vs tech users
Interaction patterns with the product
Success criteria per persona
Scenario Development:
Real-world use cases and how it may change under different circumstances
Edge case scenarios, be preapred for unexpected
Error conditions
Expected Behavior Documentation:
Success criteria per persona, per use case, per pattern
Acceptable variation ranges
Error handling expectations
Performance requirements
Test Automation Implementation
Test Infrastructure:
Testing frameworks setup
CI/CD integration
Monitoring systems
Logging and analytics
Automated Test Suites:
Unit tests for deterministic components
Integration tests for AI endpoints
End-to-end workflow tests
Performance test suites
Quality Gates:
Deployment criteria for each prompt
Performance thresholds
Quality metrics
Cost boundaries
This comprehensive approach ensures that your GenAI product is tested both as a software application and as an AI system, addressing the unique challenges while maintaining software engineering best practices.
Testing Principles and Best Practices
The traditional testing pyramid needs rethinking for GenAI applications. While the fundamental principles remain valuable, we must adapt them to handle the probabilistic nature of AI responses and the complexity of modern applications.
The classic testing pyramid suggests a majority of unit tests, fewer integration tests, and minimal end-to-end tests. For GenAI applications, this transforms into what we might call the "GenAI Testing Diamond." At its core lies a robust set of prompt testing and response validation, surrounded by traditional unit tests for deterministic components, crowned with comprehensive end-to-end testing that validates entire user journeys.
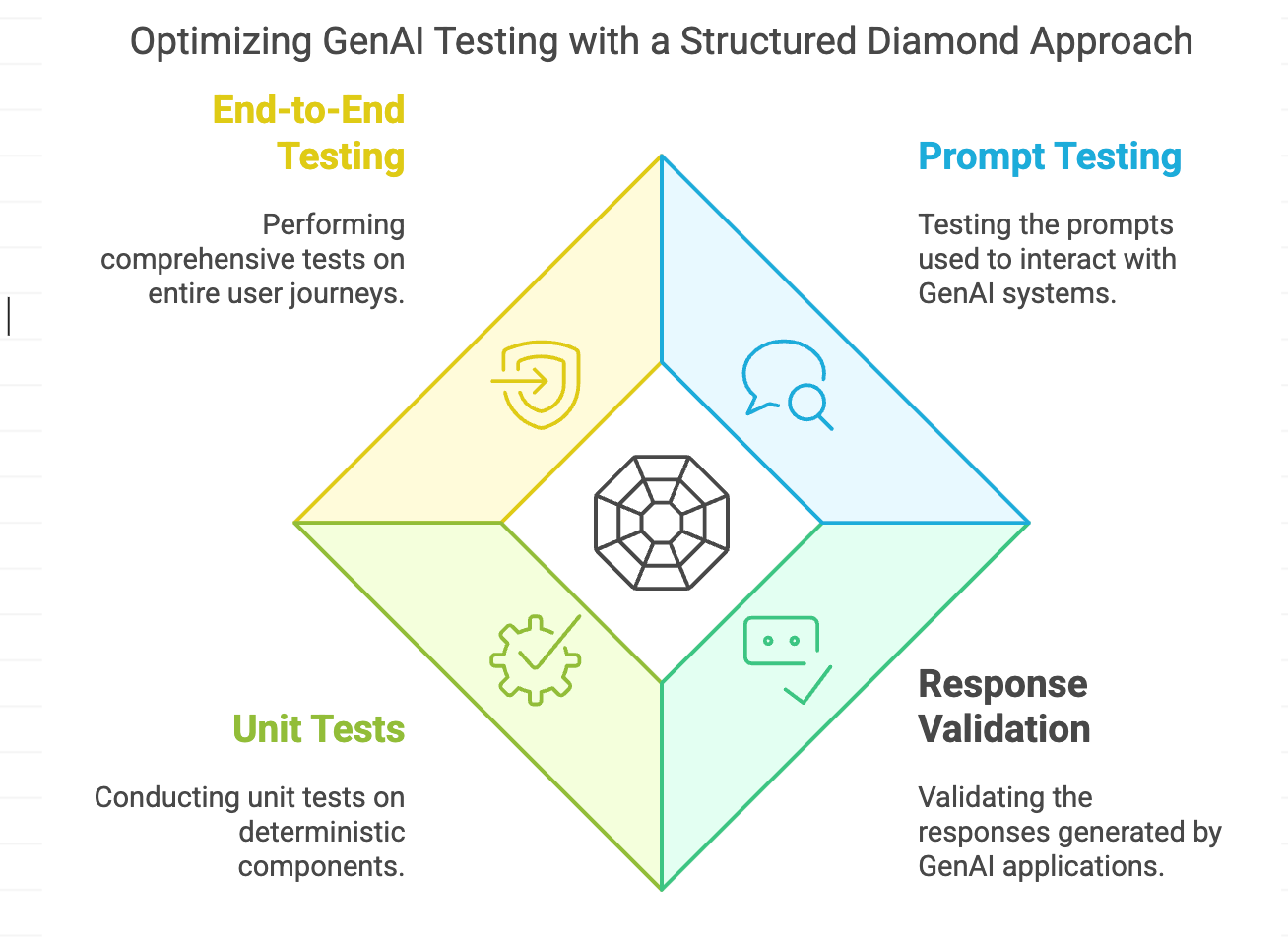
Traditional software testing principles still apply but need adaptation:
Isolation becomes more challenging when dealing with AI components
Repeatability must account for acceptable variations in AI responses
Dependencies include both traditional services and AI model behaviors
When it comes to GenAI-specific testing principles, we must consider both the technical and human aspects. The technical side involves systematic prompt versioning, robust response validation frameworks, and comprehensive error handling. The human side focuses on user experience, ethical considerations, and business value delivery.
Quality assurance processes need particular attention in GenAI applications. Review workflows must include both automated checks and human validation. Documentation becomes crucial not just for code but for prompts, expected behaviors, and acceptable response variations. Every test case should clearly articulate what constitutes a "pass" versus a "fail" when dealing with non-deterministic outputs.
Advanced Testing Strategies
A/B testing takes on new significance in GenAI applications. Beyond traditional UI variations, we're testing different prompt structures, model parameters, and even entire conversation flows. This requires sophisticated tooling and careful metrics definition.
Consider testing a customer service AI application. You might simultaneously test:
Different prompt structures for the same intent
Various response formats for similar information
Alternative conversation flows for complex queries
Different model parameters for response generation
Load testing becomes particularly crucial due to the cost and latency implications of AI API calls. You need to understand:
How your system behaves under various load patterns
The impact of concurrent API calls on response times
Cost implications of different usage patterns
Performance degradation characteristics
Security testing must address novel attack vectors specific to GenAI:
Prompt injection attempts
Data extraction through careful querying
Model behavior manipulation
Resource exhaustion attacks
Compliance testing takes on additional dimensions:
Data privacy regulations
Industry-specific compliance requirements
Ethical AI guidelines
Bias detection and mitigation
Monitoring and Maintenance
Production monitoring for GenAI applications requires attention to both traditional metrics and AI-specific indicators. A comprehensive monitoring strategy should track:
Performance Metrics:
Response times across different request types
Token usage patterns
API error rates and types
System resource utilization
Quality Metrics:
Response relevance scores
User satisfaction indicators
Task completion rates
Error recovery effectiveness
Cost Optimization:
Token usage efficiency
API cost per transaction
Caching effectiveness
Resource utilization patterns
Continuous improvement processes should include:
Regular prompt optimization
Model performance evaluation
User feedback integration
System efficiency improvements
Incident response requires specialized approaches:
AI-specific debugging tools
Response analysis capabilities
Prompt debugging frameworks
Root cause analysis methods
Future Considerations
The landscape of GenAI testing is rapidly evolving. Several key trends and considerations will shape future testing approaches:
Emerging Tools and Frameworks:
Automated prompt testing tools
AI response validation frameworks
Performance optimization tools
Security testing suites
We're seeing the development of specialized testing tools that understand the unique challenges of GenAI applications. These tools can automatically generate test cases, validate responses against complex criteria, and monitor for potential issues.
Industry Standards are beginning to emerge:
Best practices for prompt engineering
Quality metrics for AI responses
Performance benchmarks
Security guidelines
Regulatory considerations are becoming increasingly important:
AI transparency requirements
Explainability standards
Fairness metrics
Privacy protections
The future of GenAI testing will likely involve:
More sophisticated automated testing tools
Better standardization across the industry
Clearer regulatory frameworks
Improved metrics for quality assessment
The field must also prepare for new challenges:
Testing multimodal AI applications
Handling increasingly sophisticated AI capabilities
Managing complex AI interactions
Addressing emerging security threats
The key to success in this evolving landscape is maintaining flexibility in testing approaches while ensuring robust coverage of both traditional software concerns and AI-specific challenges. Organizations must stay informed about emerging best practices and be ready to adapt their testing strategies as the technology continues to advance.
Any specific area you like me to expand on here ? Hit reply and let me know.